Android™ x86 Support
Gepostet am 12. August 2014

Android™ Tablets und Smartphones mit Intel Atom CPUs erfreuen sich immer größerer Beliebtheit. Daher bietet die Murl Engine seit Version 1.00.4754Beta auch die Möglichkeit, Android Apps mit nativer x86-Unterstützung zu erstellen.
Kurz zusammengefasst:
- Murl Engine beinhaltet auch Android™ x86 Libs
- Android™ x86 Support ist standardmäßig aktiviert
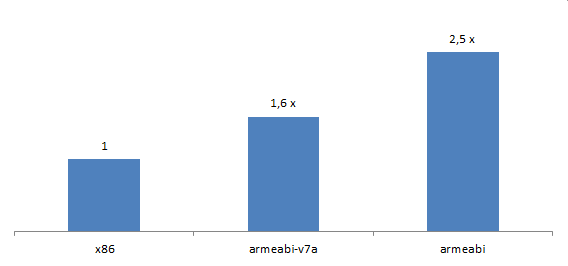
- Performance-Steigerung von ca. 1,6x bzw. 2,5x
Hintergrund
In der Vergangenheit waren Android™ Geräte typischerweise mit einer ARM CPU ausgestattet. Seit dem Jahr 2012 gibt es aber auch Android™ Geräte mit Intel x86 Atom CPUs auf dem Markt. Einige bekannte Vertreter von Android™ Geräten mit Intel CPUs sind: Samsung Galaxy Tab 3 10.1, Asus MemoPad FHD 10, Dell Venue 7/8, Motorola Razr I, Lenovo K900 oder das HP 7.
Damit bestehende Apps mit nativen ARM Code auch auf Android™ Geräten mit Intel x86 Architektur lauffähig sind, wurde von Intel ein "Binär-Übersetzer" (Binary Translator, BT) namens "Houdini" entwickelt. Dieser Binary Translator liest die nativen ARM Befehle und übersetzt sie on-the-fly in äquivalenten x86 Code.
Daher laufen die meisten ARM NDK Applikationen ohne Änderungen auch auf x86 Android™ Geräten. Allerdings kann diese "NDK Bridging Technology" auch Probleme und Geschwindigkeitseinbußen mit sich bringen. Daher sind eigene Android™ x86 Bibliotheken in den meisten Fällen empfehlenswert.
Wie gehts
Alle zukünftigen Releases der Murl Engine beinhalten auch die vorkompilierten Bibliotheken für Android™ x86. Die Android™ Build-Umgebung erzeugt und inkludiert standardmäßig auch den Android™ x86 Code.
Mit dem Parameter MURL_ANDROID_CPUS im Common-Make-file projekt/common/gnumake/module_yourapp.mk können explizit die zu unterstützenden CPU Architekturen angegeben werden. Beispiel:
MURL_ANDROID_CPUS += armeabi-v7a
MURL_ANDROID_CPUS += x86
Die angegebenen Werte entsprechen dem APP_ABI Parameter der Android™ NDK Build Umgebung (ABI steht für "Application Binary Interface").
armeabi ARM-basierende CPUs, die zumindest das ARMv5TE instruction set unterstützen.
armeabi-v7a ARM-basierende CPUs, die das ARM v7-a instruction set mit Thumb-2 Befehlen und
VFPv3-D16 Hardware FPU unterstützen.
x86 x86-basierende CPUs. Der Build erfolgt mit folgenden gcc flags:
-march=i686 -mtune=atom -mstackrealign -msse3 -mfpmath=sse -m32
Die Murl Engine Build Skripten aktivieren für x86 zusätzlich den Parameter -mssse3. Dies ist möglich, da alle x86 Android™ Geräte SSSE3 unterstützen (siehe auch https://ph0b.com/improving-x86-support-of-android-apps-libs-engines). Weitere Informationen über die verschiedenen Architekturen können in der NDK Dokumentation unter docs/CPU-ARCH-ABIS.html nachgelesen werden.
Um zu überprüfen, ob die richtigen Bibliotheken inkludiert wurden, genügt ein Blick in das lib Verzeichnis des APK Archivs. Bekanntermaßen sind .apk Dateien gezippte Archive, die z.B. einfach in .zip Dateien umbenannt und mit einem beliebigen Komprimierungs-Tool entpackt werden können.
Ist es den Aufwand wert?
Wie groß der Geschwindigkeitsvorteil bei Verwendung von x86 Code gegenüber dem Binary Translator tatsächlich ist, hängt logischerweise von der Art der Anwendung, den verwendeten Features und nicht zuletzt von der Version des Binary Translators ab. Um ein besseres Gefühl zu bekommen, haben wir ein paar simple Benchmarks mit der Murl Engine durchgeführt. Bitte zu beachten, dass es sich dabei lediglich um einfache Tests handelt und sich davon keine allgemeine Aussage über die Leistungssteigerung ableiten lässt. Gegebenenfalls sollten eigene Tests durchgeführt werden.
Als Testgerät wurde ein Asus Memo Pad FHD 10 verwendet, das uns freundlicherweise von Intel zur Verfügung gestellt wurde. Das Tablet ist mit einer Dual-Core 1,6 GHz Intel® Atom™ Z2560 CPU mit integrierter PowerVR SGX544 GPU ausgestattet und hat ein 10.1 Zoll WUXGA Display mit einer Auflösung von 1920 x 1200 Pixeln.
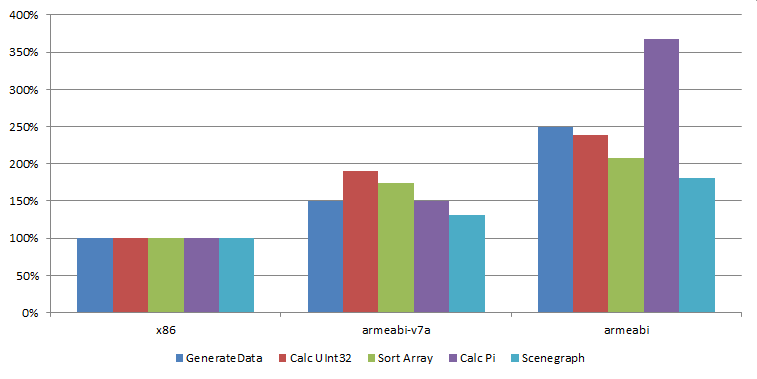
Unsere Tests mit der Murl Engine zeigten, dass armeabi-v7a Code im Durchschnitt um den Faktor 1.6 langsamer läuft (bzw. um den Faktor 2.5 bei armeabi Code). Je nach Benchmark lagen die Werte zischen 130% und 190% (bzw. zwischen 180% und 370% für armeabi). Genauere Informationen zu den durchgeführten Tests sind weiter unten zu finden.
Speicherplatz
Natürlich erhöhen die zusätzlichen x86 Dateien den Gesamtspeicherplatz des APK-Archivs. Wenn die Speichergröße ein kritischer Faktor ist, kann die APK-Datei auch gesplittet werden, sodass für jede CPU Architektur ein eigens APK-Archiv existiert. Dabei ist zu beachten, dass die Versionsnummern der x86 APK-Datei größer der Versionsnummer der ARM Version sein muss (Parameter MURL_ANDROID_VERSION_CODE im Common-Make-file).
x86 version code > armeabi-v7a version code > armeabi version code
Der Play-Store liefert dann die APK mit der höchsten Versionsnummer die noch kompatibel ist aus. Weitere Informationen dazu können in der Android™ Developer Dokumentation unter Multiple APK Support nachgelesen werden.
Benchmarks
Die Tests wurden mit dem Asus Memo Pad FHD 10 durchgeführt. Die angegebenen Werte sind ein Maß für die benötigte Rechenzeit. Höhere Werte sind schlechter als niedrige Werte.
Übersicht
| x86 | armeabi-v7a | armeabi | |
|---|---|---|---|
| GenerateData | 100% | 150% | 249% |
| Calc UInt32 | 100% | 190% | 239% |
| Sort Array | 100% | 174% | 208% |
| Calc Pi | 100% | 149% | 367% |
| Scenegraph | 100% | 131% | 180% |
GenerateData
Erzeugen von 20.000.000 zufälligen Werten und Speicherung in drei anfänglich leeren Containern (UInt32Array, FloatArray, DoubleArray).
Util::TT800 rng(42);
UInt32Array uInt32Array;
FloatArray floatArray;
DoubleArray doubleArray;
for (UInt32 i = 0; i < mMax; i++)
{
UInt32 val = rng.Rand();
uInt32Array.Add(val);
floatArray.Add(Float(val));
doubleArray.Add(Double(val));
}
| t [ms] | x86 | armeabi-v7a | armeabi |
|---|---|---|---|
| Mittelwert | 5.837 | 8.728 | 14.517 |
| Rel. Standardabweichung | 0,99% | 0,79% | 1,79% |
| Rel. Differenz | 100% | 150% | 249% |
Calc UInt32
Berechnung einer Zahl aus den erzeugten 20.000.000 zufälligen UInt32 Werten.
UInt32 a = 0;
UInt32 lastIndex = uInt32Array.GetCount() - 1;
for (UInt32 i = 0; i < lastIndex; i++)
{
a += (uInt32Array[lastIndex-i] * uInt32Array[i]) / 2147483648;
}
| t [ms] | x86 | armeabi-v7a | armeabi |
|---|---|---|---|
| Mittelwert | 130 | 247 | 310 |
| Rel. Standardabweichung | 0,00% | 2,34% | 0,00% |
| Rel. Differenz | 100% | 190% | 238% |
Sort Array
Sortiere ein UInt32Array mit 2.000.000 zufälligen Zahlen mittels Quicksort.
Util::SortArray(uInt32Array, false);
| t [ms] | x86 | armeabi-v7a | armeabi |
|---|---|---|---|
| Mittelwert | 1.581 | 2.753 | 3.282 |
| Rel. Standardabweichung | 0,46% | 0,76% | 1,09% |
| Rel. Differenz | 100% | 174% | 208% |
Calc PI
Berechne die Zahl PI nach der Leibniz-Reihe mit 40.000.000 Summanden.
Double quaterpi = 1;
UInt32 divisor = 3;
for (UInt32 i=0; i < mMax; i++)
{
quaterpi -= Double(1) / divisor;
divisor += 2;
quaterpi += Double(1) / divisor;
divisor += 2;
}
| t [ms] | x86 | armeabi-v7a | armeabi |
|---|---|---|---|
| Mittelwert | 1.933 | 2.883 | 7.093 |
| Rel. Standardabweichung | 0,05% | 0,14% | 0,08% |
| Rel. Differenz | 100% | 149% | 367% |
Scenegraph
Szenegraphprocessing eines Szenengraphen mit 20.000 Sprite Objekten, die an zufälligen Positionen gerendert werden.
SInt32 widthX = (state->GetAppConfiguration()->GetDisplaySurfaceSizeX() - 64) / 2;
SInt32 widthY = (state->GetAppConfiguration()->GetDisplaySurfaceSizeY() - 64) / 2;
Graph::IRoot* root = state->GetGraphRoot();
const Graph::INodeArray& spriteList = mSpriteGroup->GetChildren();
UInt32 count = spriteList.GetCount();
Util::TT800 rng;
for (UInt32 i = 0; i < count; i++)
{
Graph::ITransform* node = (dynamic_cast<Graph::IPlaneGeometry*>(spriteList[i]))->GetTransformInterface();
node->SetPosition(rng.RandSInt(-widthX, widthX),rng.RandSInt(-widthY, widthY),0);
}
| t [ms] | x86 | armeabi-v7a | armeabi |
|---|---|---|---|
| Mittelwert | 129,1 | 169,6 | 233,0 |
| Rel. Standardabweichung | 2,45% | 1,05% | 2,00% |
| Rel. Differenz | 100% | 131% | 180% |
![]()
Beim Newsletter anmelden
und keine News-Updates mehr verpassen.